Objektové, nebo chcete-li, dokumentové, databáze jsou v praxi práce s prostorovými daty poměrně neobvyklé. Jistě, občas se zaslechne něco o NOSQL, uvidí se zajímavý blog, pěkná prezentace, ale o nasazení nad skutečnými daty je možné zaslechnout pouze sporadicky. Přitom v databázovém světě je toto téma skloňováno velmi často, NOSQL datábáze jsou zhusta používány na webových aplikacích. Nezřídka se o nich hovoří ve spojitosti s big data.
Protože nebyl zrovna po ruce nikdo, z koho bych mohl tahat rozumy, nezbylo mi, než abych si na věc udělal názor sám. Věnoval jsem tomu pár večerů, mé závěry si tedy nekladou ambice na nějakou definitivnost, musel jsem se popasovat s technologiemi, které mi dosud nic neříkaly, takže není vyloučené, že mi něco podstatného uniklo.
Podělím se s vámi o závěry, které jsem udělal a o pár, domnívám se, užitečných ukázek a postřehů. Názor, jestli má cenu toto téma rozvíjet, si udělejte sami. Já osobně se domnívám, že ano, nicméně jedná se o řešení pro specifický use case, rozhodně si nemyslím, že NOSQL databází je možné plnohodnotně nahradit klasickou relační databázi.
Mongo pracuje s daty ve formátu json. Data jsou členěna do databází a databáze dále do collections (nevím, jestli existuje nějaký obvyklý způsob, jak tento termín překládat, proto ho nechám, jak je). Json je možné proindexovat po jednotlivých polích.
Tady starej relačník namítne: “To je možný i v PostgreSQL a ještě líp, dají se tam ukládat do sloupců jsony, bsony a dá se to indexovat funkcionálním indexem. Tak proč se hmoždit s nějakým mongo”. Jistě to je pravda. Jde to udělat i v Postgre, což přináší nějaké výhody a nějakej overhead. Je třeba to vyzkoušet a porovnat…
Mongo se dotazuje pomocí jsonů (a jsme u té výhody oproti PostgreSQL), což je pro určitá nasazení náramně výhodné. Na nějaké joiny a vazby však můžete rovnou zapomenout. Všechno se to musí uložit do jsonů. Co má být pohromadě, musí být pohromadě. Veškerá logika musí být na aplikaci. Zde je patrné, že v některých případech nám budou data redundantnět. Což na druhou stranu nemusí být takový problém.
NOSQL databáze přichází ke slovu ve chvíli, kdy bychom v relační databázi data byli nuceni rozdělit do mnoha provázaných tabulek a jen samotné udržování integrity by nám hrozilo nadělat z mozku vejce na hniličko. Data ve stromové struktuře, různě naplněná, která vám stačí dotazovat tak jak jsou. Učesat je do relační databáze je zbytečná práce, rozházíte je do tabulek jen proto, abyste z nich byli schopní opět poskládat to, co jste do nich pracně dostávali. Šoupnete to do NOSQL a pokud nic nepomršíte, tak se budete schopní relativně rychle doptat na libovolný vstupní objekt.
Dejme tomu, že sbíráte data o kvalitě vody, měříte pH, vodivost, fosfor, dusík, kyslík. Jednotlivé odběry provádíte na různých lokalitách, u toho sledujete počasí, čas. Každé měření několkrát opakujete, potřebujete vědět kdo měřil a jakým přístrojem. Vaše data pak mohou vypadat třeba takto:
{
"id_odberu" : 1,
"pracovnik": "Jakub Ryba",
"datum":"2009-10-12T10:30:00",
"lokalita":"Dědova brada",
"GPS":{"type" : "Point",
"coordinates" : [
12.639870657036909,
50.18803879095269
]
},
"stanoviste":"potůček zurčící mechem a kapradím",
"pocasi":{
"teplota": -3,
"oblacnost": 0,
"smer_vetru": "SZ",
"sila_vetru": 5
},
"pozn": "ke svačině jsem měl chleba s vysočinou",
"data": {
"Ph": {
"pristroj_typ":"eta_12",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6,7,8,9,10]
} ,
"vodivost": {
"pristroj_typ":"blabla",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6,7,8,9,10]
} ,
"N": {
"pristroj_typ":"pws 750-125",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6]
} ,
"P": {
"pristroj_typ":"pws 750-125",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6]
} ,
"O": {
"pristroj_typ":"pws 750-125",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6]
} ,
"viditelnost_secchi_disk": {
"pristroj_typ":"spodek od květináče na tkaničce od boty",
"pristroj_vyrobni_cislo":12345678,
"hodnoty":[1,2,3,4,5,6]
}
}
}
A k tomu si přidejte, že ne na každé lokalitě se měří všechny hodnoty a podobných měření máte několik tisíc. Jistě, tohle se ještě dá, poměrně snadno, dostat do relační databáze, nicméně pro některé aplikace je to zbytečné a pokud budete data od terénních pracovníků dostávat takto, může být jejich normalizování pro relační databázi zbytečné.
Z NOSQL databáze přitom můžete poměrně snadno vybírat hodnoty na základě celkem složitých kritérií. Například: najdi mi všechna měření do deseti kilometrů od Kolína provedená za jasného počasí v lednu 2013, kdy alespoň jedna ze zjištěných hodnot fosforu byl větší než x.
S ohledem na to, že se data do monga ukládají v (b)jsonech, asi nikoho nepřekvapí, že geodata budeme do monga ládovat v geojsonech. Nicméně nabídka prostorových funkcí je poměrně chudá, mongo sice umí pracovat jak s lat/lon, tak s projekcí, nicméně data s hodnotami mimo rozsah -180..180 neoindexujete a prostorové dotazy taktéž nebudou fungovat. S křovákem zkrátka nepochodíte. Taktéž nevalidní geometrie (self intersect) prostorovým dotazem nevyberete a budou bez varování vynechána. Nicméně můžete samozřejmě oindexovat bounding box a přesnější srovnání provádět na aplikaci, což je pro mnohá využití naprosto dostačující.
Pro pokusné účely jsem připravil skript v pythonu, kterým naimportujete do monga data z RUIAN. Aby vám chodil, musíte mít nainstalované pro python moduly pymongo, ogr a simplejson. Skript je testován pro python2.7 (aby bylo možné ho používat z QGisu).
Případně můžete použít přežvýkané parcely pro Sokolov. Bohužel však do jsonu není možné vložit oblouk a tak jsou oblouky převáděné na lomené čáry, což může vést ke ztrátě validity a znemožnit prostorové indexování. Data jsou v rámci skriptu převedena do souřadnicového systému WGS84.
Mongo nainstalujeme pomocí našeho balíčkovacího systému.
Na mém systému (arch linux) ho spouštím.
sudo systemctl start mongodb.service
Následně se přesvědčím, zda skutečně běží.
sudo systemctl status mongodb.service
Pokud spustíte
mongo
Měli byste být v příkazové konzoli monga.
Pokud vám mongo neběží, věnujte pozornost konfiguračnímu souboru /etc/mongodb.conf. Obvyklým problémem bývá nedostatek místa, mongo k rozeběhnutí potřebuje minimálně 3Gb místa na journály. Dalším problémem mohou být práva ná zápis do logu, u mě to vyřešilo zakázání logAppend:
cat /etc/mongodb.conf # See http://www.mongodb.org/display/DOCS/File+Based+Configuration for format details # Run mongod --help to see a list of options bind_ip = 127.0.0.1 quiet = true #auth = true ##authentication enabled #dbpath = /var/lib/mongodb dbpath = /home/data/mongodb logpath = /var/log/mongodb/mongod.log logappend = false
Ukázková data importujeme
mongoimport --db mongo_memorizer --collection Parcely --drop --file sample.json
Za předpokladu, že máme mongo puštěné bez autentizace.
Případně můžeme stáhnout a rozbalit pár souborů ruian a namigrovat je pomocí mongolizéru.
./mongolizer.py --ruian_file 20151031_OB_560286_UKSH.xml --db db_pro_import
Nyní se můžeme pokochat importovanými daty přímo v konzoli monga.
mongo db_pro_import
show databases
show collections
db.Parcely.findOne()
db.Parcely.find().count()
db.Parcely.findOne({"geometry":{$exists:1}})
db.Parcely.findOne({"geometry":{$exists:1}}).geometry_p
db.Parcely.find({"properties.Id":31525565010})['properties']
Prvním příkazem se připojíme do monga, do vybrané databáze (mezi databázemi přepínáme pomocí use database. Dalším pak zobrazíme všechny databáze, následuje potom příkaz, který zobrazí collections. findOne() nám vrátí jeden prvek, find() všechny. count() nepřekvapivě vrátí počet prvků v dotazu. Jak find, tak findOne můžeme zadat pomocí jsonu, jaké parametry musí splňovat vrácený prvek/prvky. Pomocí $ jsou uváděny operátory operátor $exists slouží k otestování, zda prvek má požadovaný uzel. Z vráceného prvku můžeme vybírat zanořené uzly buď pomocí tečky a nebo uvedením klíče v hranatých závorkách (jako v pythonu). Pokud dotazujeme zanořené uzly, oddělujeme je tečkou (jak je tomu na posledním řádku).
Další zajímavé operátory jsou třeba $regex, který umožňuje porovnávat hodnotu s regulárem. A samozřejmě prostorové operátory, nebo operátor $where, který umožňuje evaluovat javascriptovou funkci.
Pokud vám prohlížení geojsonů v mongo konzoli nevyhovuje, můžete vyzkoušet plugin do Qgisu mongo_memorizer, který jsem si v rámci svých pokusů s mongem napsal. Jeho použití je popsáno v help.rst. Pokud si ho rozbalíte do své složky s qgisími pluginy a vybildíte, měl by se Vám objevit v nabídce instalovaných pluginů.
Build na linuxu
make -B
Build na windows (je třeba nainstalovat Osgeo4w)
pyrcc4 -o resources.py resources.qrc
Nově je plugin přidaný i v oficiálním Qgis repozitáři takže ho lze instalovat přímo z plugin manageru Qgisu.
Aby plugin fungoval, je třeba nainstalovat do pythonu 2.7 moduly pymongo a simplejson.
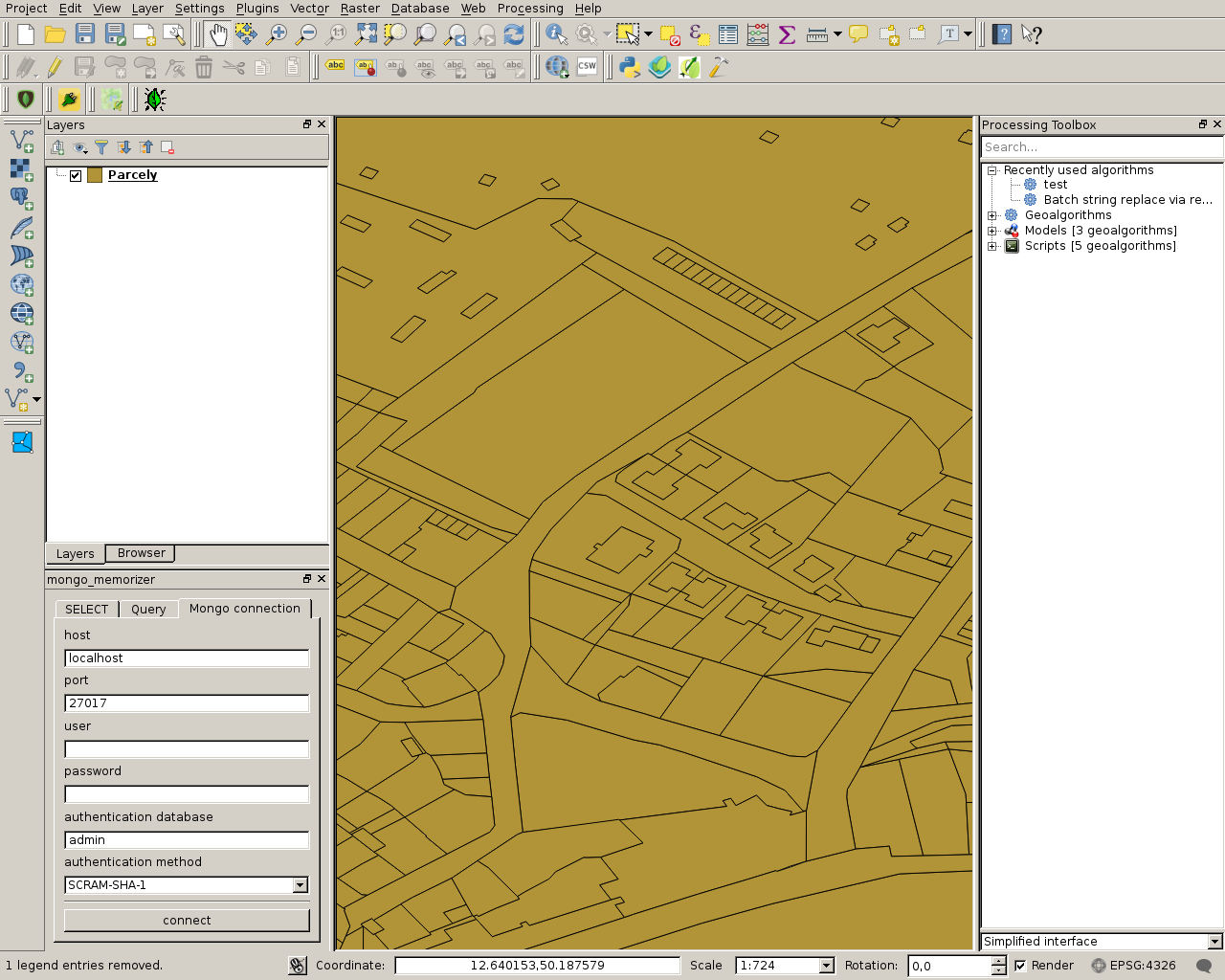
Je možné si v něm vyzkoušet různé dotazy do mongo databáze a výsledky se zobrazí jako Qgis vrstva, včetně tabulky.
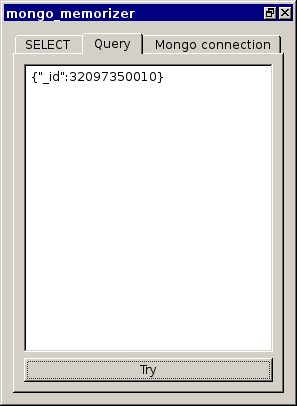
Položky, na základě kterých budeme chtít vybírat je vhodné oindexovat (u deseti tisíc parcel to asi nedává velký smysl). Položka _id, obdoba primárního klíče u monga je indexována defaultně.
Indexy na collection zobrazíme pomocí getIndexes
db.Parcely.getIndexes()
Nový index na položku přidáme pomocí createIndex. Položku KmenoveCislo v properties oindexujeme pomocí createIndex.
db.Parcely.createIndex({"properties.KmenoveCislo":1})
Samozřejmě je možné vytvářet složené indexy přes více položek.
db.Parcely.createIndex({"properties.KmenoveCislo":1, "properties.PododdeleniCisla":1})
Index má však limit 1024 bytů na položku, extrémně velké položky není možné indexovat.
Mongo zná tři druhy prostorových indexů 2d index pro projekci, 2dsphere index pro referenční elipsoid a Haystack index. My se budeme zabývat pouze 2dsphere indexem.
Index vytvoříme příkazem
db.Parcely.createIndex({"geometry":"2dsphere"})
A ouha, padla kosa na kámen. Problémem je, že mám v databázi nevalidní polygony. Chyba vznikla tak, že ve vstupních souborech jsou totiž oblouky a ty nelze uložit do geojsonu. Musel jsem tedy oblouky převést na lomené čáry, což způsobilo na několika místech self intersecty. Nepodařilo se mi najít postup, kterým bych tyto situace ošetřil (ani obligátní Buffer(0) nefungoval dle očekávání). Mohl bych geometrie opravit, ale já je prostě vymažu (i když bude výstupní vrstva potom lehce připomínat noty na buben).
db.Parcely.remove({"_id":456309409})
Teď už se mi 2dsphere index podaří vytvořit.
Další možnost, samozřejmě je, oindexovat položku geometry_p s definičními body, nebo si vytvořit bounding boxy.
Používání prostorových dotazů není přímo podmíněno vytvořením prostorového indexu, jak by se mohlo jevit z dokumentace monga. Nicméně z indexování nikdy nikomu ručičky neupadly, takže si ukážeme pár dotazů na naši oindexovanou geometrii.
Můžeme použít tři základní operátory $geoWithin, $geoIntersects a $geoNear.
Z názvů je celkem patrné, k čemu oprátory slouží, takže to nebudu dále rozvádět, případně opakovat dokumentaci monga.
Příklad. Najdeme si budovu (collection StavebniObjekty) na parcele a podíváme se, jestli nám jí mongo bude umět najít v prostoru.
//najdu si id parcely, na ktere lezi budova
var par_id =
db.StavebniObjekty.findOne({"properties.IdentifikacniParcela":{"$exists":1}}).properties.IdentifikacniParcela.Id
//vezmu jeji geometrii
var par_geom = db.Parcely.findOne({"_id":par_id}).geometry
//dotazi se zpet na budovu, ktera lezi na parcele
db.StavebniObjekty.find({"geometry":{"$geoWithin":{"$geometry":par_geom}}})
Tento příklad funguje, nicméně v rámci prostorových indexů a dotazů nás čeká v mongu pár celkem nepěkných kulišáren. Ne každý operátor funguje s každou geometrií, něco potřebuje přepočítat hodnoty z radiánů (WTF) a použitá terminologie v dokumentaci se příliš nekryje s běžnou geoinformatickou terminologií.
Například zadání:
Bdělý občan potkal na souřadnicích "12.66901,50.17608" komeníka. Které budovy bude třeba evakuovat pro případ, že by se jednalo o zakuklenýho teroristu.
Jsem zkoušel řešit pomocí oprátotu $centerSphere a bezůspěšně, i když jsem celé řešení obšlehl z tutoriálu. Pravděpodobně je problém s výpočty na geoidu, nepřišel jsem na to, jak napsat dotaz, aby fungoval (na datech z tutoriálu ukázkový dotaz funguje).
Samozřejmě si mohu spočítat buffer vedle, například pomocí turf, uložit do porměnné a použít stejný postup jako v příkladu výše.
Pokud se Vám nabídka prostorových (nebo jakýchkoliv jiných) funkcí zdá nedostatečná, lze si, vzhledem k tomu, že mongo konzole funguje jako javascriptový interpreter, vypomoci javascriptovými knihovnami. Mě se podařilo nahrát do monga javascriptovou knihovnu turf která umožňuje práci s prostorovými objekty. Javascriptové funkce si můžete samozřejmě pro mongo napsat i sami. Turf a jsts jsem si naimportoval pomocí npm.
Javascriptové soubory importujeme pomocí load. Je třeba však brát v potaz, že nejsou nahrané na serveru, ale pouze v našem interpreteru a po ukončení session zmizí. Proto se mi jako efektivnější postup zdá použití pythonu, napojení na mongo pomocí modulu pymongo a zpracování geometrií například pomocí knihovny ogr. Nicméně použít javascriptové knihovny tímto způsobem jde a můžete si takto napříkklad odladit postupy, které posléze poběží v prohlížeči.
load('node_modules/jsts/lib/javascript.util.min.js')
load('node_modules/jsts/lib/jsts.min.js')
load('node_modules/turf/turf.min.js')
var x = db.Parcely.findOne()
turf.buffer(x,1,'meters')
db.Parcely.find().limit(100).forEach(function(x) {print(x._id, turf.area(x))})
Jako ideální nástroj se mě osobně jeví python s modulem pymongo, který umožňuje sahat pro data z pythonu do monga a přitom využívat našlapaných knihoven pro práci s geodaty, které umí načítat geojson.
V následující ukázce je naznačeno, jak je v pluginu realizován filtr podle mapového okna. Dotaz je v pthoním slovníku, geometrie je získána z objektu qgisu iface.
#pripojim se ne mongo
self.con = MongoClient()
#vyberu db
self.db = self.con[dbname]
#vyberu collection
self.collection = self.db[collectionname]
#prostorový dotaz je python dict
spatial_query = {"$geoIntersects":
{"$geometry":
json.loads(ogr.CreateGeometryFromWkt(
#vezmu polygon definující extent mapového okna
self.iface.mapCanvas().extent().asWktPolygon()).ExportToJson())
}
}
#filtr aplikuji na položku s geometrií
self.cur = self.collection.find({geomcolname : spatial_query})
Jak je z uvedených příkladů patrné. Mongo si velice dobře rozumí s javascriptem, napojení monga na javascript je v podstatě bezešvé. Nebudu dávat žádné příklady, jednak je to proto, že javascriptu nerozumím a jednak většina příkladů na použití monga na prostorové věci je právě v javascriptu, tudíž si snadno můžete dohledat příklady a snipety a já opravdu nechtěl otrocky přebírat a ohýbat příklady, kterým zcela nerozumím. Navíc jsem nechtěl všechnu legraci vyžrat sám a nechávám zde prostor, ve kterém se může realizovat nějaký z mých kolegů, pro kterého není javascript španělská ves.
Nicméně dovedu si celkem jednoduchou aplikaci založenou na mongu, openlayers a turfu, která by nabízela relativně zajímavou nabídku funkcionalit a přitom by stačilo v podstatě jen “zacvaknout” do sebe již existující věci. A to nemluvím o takových třešničkách na pečivu, jako je “offline editace” nad kusem dat staženým do jsonů a následnou synchronizací s databází/upsertem. Což je věc, která se tady přímo nabízí a její implementace ve složitější relační struktuře je záludná a netriviální.
Mongo lze propojit s PostgreSQL a collections přidávat jako cizí tabulky pomocí FDW wrapperu, kterých existuje několik. Já tuto možnost netestoval.
Mongo rozhodně není jediná NOSQL databáze s podporou prostorových prvků. Často bývá zmiňováno například rozšíření GeoCouch NOSQL databáze CouchDB, která navíc nabízí, na rozdíl od Monga REST API.
Za GISMentors Jan Jelen Michálek
